

Design of Noteburst, a programatic JupyterLab notebook execution service for the Rubin Science Platform#
Abstract
Jupyter Notebooks are a widely used medium in Rubin Observatory for communicating through documentation and executable code. Until now, Jupyter Notebooks have only been accessible from the Notebook Aspect (Nublado/JupyterLab, SQR-018 [Economou and Thornton, 2019]) of the Rubin Science Platform (DMTN-212 [Economou, 2023]). There are applications where we can benefit from “headless” execution of Jupyter notebooks through a web API, such as preparing status dashboards (Times Square, SQR-062 [Sick, 2021]), and continuous integration of code samples in documentation. This technical note discusses the architectural design details of such a service, called Noteburst.
Links#
This technical note provides an overview of Noteburst’s design and implementation. Lower-level information can be found elsewhere:
lsst-sqre/noteburst on GitHub
API documentation endpoints, such as https://data-dev.lsst.cloud/noteburst/docs
Use cases#
These are examples of applications that are either enabled by, or can benefit from, a headless Jupyter Notebook service co-located on the Rubin Science Platform.
Times Square#
In the Times Square (SQR-062, [Sick, 2021]) use case, users are visiting web pages in a browser, and those pages contain HTML renderings of executed Jupyter Notebooks. Although Times Square will cache executed Jupyter Notebooks, if the user requests a novel parameterization of a notebook that isn’t in Times Square’s cache, that webpage visit will ultimately result in a request to Noteburst to execute a new notebook. Furthermore multiple users may visit different novel pages, each requiring a different execution through Noteburst.
Notebook-based technical notes#
Rubin has a robust technical note platform (SQR-000 [Sick, 2015]), that empowers staff to share technical information quickly and widely with little overhead. At the moment, technical notes are written either as Sphinx/reStructuredText or PDF (LaTeX) documents. Jupyter Notebooks can be a compelling addition to this line-up for documentation applications that combine computational analysis and visualization with prose. For example, a technical note could include an analysis of data available from the Rubin Science Platform, and all figures and tables presented in that technical note are the direct result of that computation.
Technotes are typically published through GitHub Actions, where we have upload credentials available and established workflow patterns. Rubin data or software like the LSST Science Pipelines aren’t typically available through GitHub Actions. The naive workaround is to execute the notebook on the RSP and commit the result into the technote’s GitHub repository. There are at least two downsides to this. First, the executed notebook takes more storage space because of its outputs and it generally harder to manage in a Git workflow. Second, the technote is less reproducible since there are many manual steps between executing a notebook and publish it as a technote.
The solution could be to use a “headless notebook execution” web service hosted on the Rubin Science Platform. The author commits a change to an (unexecuted) Jupyter Notebook-based technote, which triggers a GitHub Actions workflow. That workflow makes a call to the service (noteburst) using an RSP token stored in the repository’s GitHub Secrets. Once the workflow gets the executed notebook back from the web service, it uses the local CI environment to convert the notebook into HTML and publish it through LSST the Docs (SQR-006 [Sick, 2016]).
Documentation testing#
Similar to the above use-case, the ability to test sample code and examples from documentation could benefit from a service that executes code on the RSP and packages the outputs in Jupyter Notebook format. See SQR-032 [Sick, 2019] for additional ideas on this subject.
Noteburst’s architecture#
Noteburst’s design resolves around the following constraints and requirements:
Notebooks must be executed in the Rubin Science Platform with a similar, if not identical, set up to how users interactively run notebooks. A notebook that a user can run in Nublado must also be runnable through the service.
The service must be accessible through a simple HTTP interface.
The service must account for the fact that notebooks can take a significant amount of time to execute (this is, it must employ an asynchronous queue architecture).
This section describes how Noteburst is designed to meet these needs.
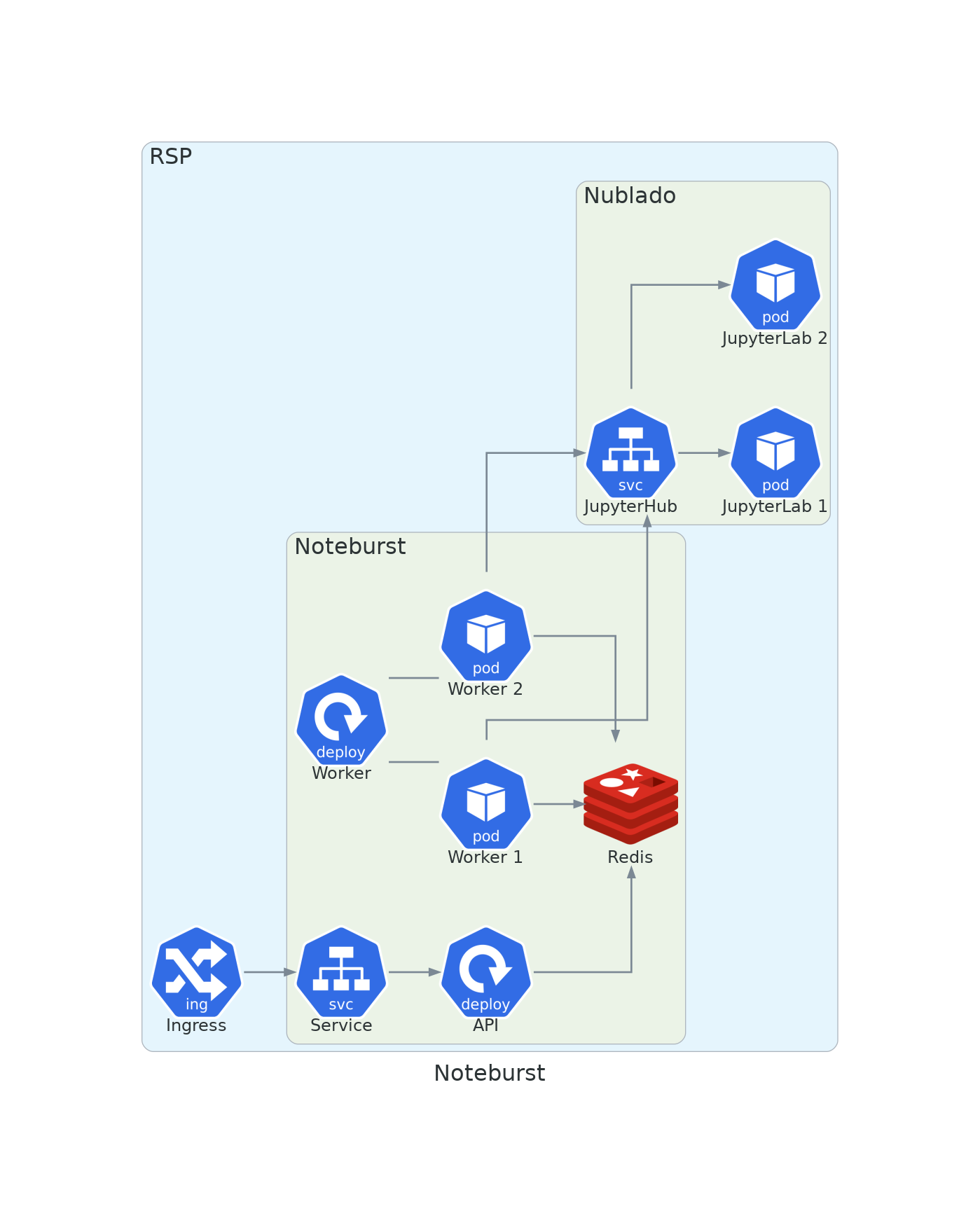
Noteburst consists of two Kubernetes application deployments: an API deployment and the worker deployment. The pods running in both deployments are drawn from the same codebase (lsst-sqre/noteburst), but the API runs a FastAPI application, while the worker pods are arq worker instances. Noteburst’s only persistent storage is a Redis cluster that contains both queue jobs and the results from completed jobs.
API deployment#
The Noteburst API deployment processes HTTP requests from clients. Through the API, Noteburst receives notebook execution requests and creates notebook execution jobs through the arq library, which are stored in Redis. The API can also retrieve results (generated by workers) from Redis, upon request.
Worker deployment#
Noteburst’s workers are responsible for executing notebooks. Each worker has a one-to-one relationship with a with a Nublado (JupyterLab) user pod. When a worker pod starts up, it starts a JupyterLab pod under a bot user identity. A connection to that JupyterLab pod is maintained for the lifetime of the worker pod. When the Noteburst worker receives a job request (through arq, from the Noteburst API deployment), it triggers a notebook execution via the execution extension endpoint in lsst-sqre/rsp-jupyter-extensions, which in turn runs nbconvert’s ~nbconvert.preprocessors.ExecutePreprocessor.
Redis deployment#
Noteburst uses Redis as its sole persistent storage. In the Phalanx deployment, Redis is deployed via a Bitnami Helm chart in high-availability mode with three nodes in total and persistent volumes for each node.
Noteburst uses Redis for two concerns:
As a global lock of claimed user identities for worker pods
As a storage backend for queued job submitted through the API pods and results submitted through the worker pods.
Mechanism for managing JupyterLab identities of workers#
Each Noteburst worker pod acts as the user for a corresponding Nublado (JupyterLab) pod. When a Noteburst worker starts up, it also spawns a JupyterLab pod (and when the Noteburst worker terminates it also ideally terminates the JupyterLab pod). This behavior implies that each running Noteburst worker must be configured with a unique RSP (bot) user identity.
To accomplish this, we use a list of user identities reserved for Noteburst. At the moment, these user identities are provided as a Kubernetes ConfigMap that is mounted by worker pods:
apiVersion: v1
kind: ConfigMap
metadata:
name: noteburst-worker-identities
data:
identities.yaml: |
- uid: 90000
username: "noteburst90000"
- uid: 90001
username: "noteburst90001"
- uid: 90002
username: "noteburst90002"
(The contents of identities.yaml is configurable via Helm values files.)
When a worker starts up, it uses an IdentityManager to acquire an identity.
The manager loops through the items in the identity.yaml configuration and queries Redis whether this identity is claimed.
If no claim for a specific identity exists, the worker claims that identity.
Claims are established and maintained through the aioredlock library, which is a Python implementation of the Redis Redlock distributed locking algorithm.
aioredlock implements a background “keep-alive” refresh on the claim for the life of the worker.
Once the worker is terminated, the claim naturally expires and the identity becomes available again.
Through this mechanism, a pool of Noteburst workers can be naturally scaled up or down on-demand simply by changing the replica count of the worker deployment.
Noteburst’s HTTP API#
Noteburst provides a simple web API.
To submit a notebook for execution, clients request POST /noteburst/b1/notebooks/ with a JSON payload that includes the Jupyter Notebook (ipynb file contents) and optionally the name of a Jupyter kernel to execute the notebook with (the default kernel is the default for interactive RSP users).
Noteburst’s response includes a Location header pointing to a URL where the client can get the result or see the current status of the job.
That result endpoint is GET /noteburst/v1/notebooks/{job_id}.
The JSON response object from this endpoint includes the status of the execution job (status field).
When the result is available, the ipynb field includes the contents of the executed Jupyter Notebook.
Under this model, clients are expected to poll the result URL. We initially considered implementing a webhook mechanism as well for Noteburst to push results to clients, however we have not yet implemented that due to the associated security engineering required.
More information about Noteburst’s API is available from the RSP environment, for example: https://data-dev.lsst.cloud/noteburst/docs
API security#
Gafaelfawr authenticates and authorizes access to the Noteburst API (DMTN-193, [Allbery, 2022]).
At the moment, users of Noteburst need tokens with exec:admin scope (i.e., Noteburst is considered an administrative API).
References#
[DMTN-193]. Russ Allbery. Web security for the Science Platform. 2022. Vera C. Rubin Observatory Data Management Technical Note. URL: https://dmtn-193.lsst.io/
[DMTN-212]. Frossie Economou. The Rubin Science Platform. 2023. Vera C. Rubin Observatory Data Management Technical Note. URL: https://dmtn-212.lsst.io/
[SQR-018]. Frossie Economou and Adam Thornton. Investigations into JupyterLab as a basis for the LSST Science Platform. 2019. Vera C. Rubin Observatory SQuaRE Technical Note. URL: https://sqr-018.lsst.io/
[SQR-000]. Jonathan Sick. The LSST DM Technical Note Publishing Platform. 2015. Vera C. Rubin Observatory SQuaRE Technical Note. URL: https://sqr-000.lsst.io/
[SQR-006]. Jonathan Sick. The LSST the Docs Platform for Continuous Documentation Delivery. 2016. Vera C. Rubin Observatory SQuaRE Technical Note. URL: https://sqr-006.lsst.io/
[SQR-032]. Jonathan Sick. Rendering and testing examples and tutorials in LSST documentation. 2019. Vera C. Rubin Observatory SQuaRE Technical Note. URL: https://sqr-032.lsst.io/
[SQR-062]. Jonathan Sick. The Times Square service for publishing parameterized Jupyter Notebooks in the Rubin Science platform. 2021. Vera C. Rubin Observatory SQuaRE Technical Note. URL: https://sqr-062.lsst.io/